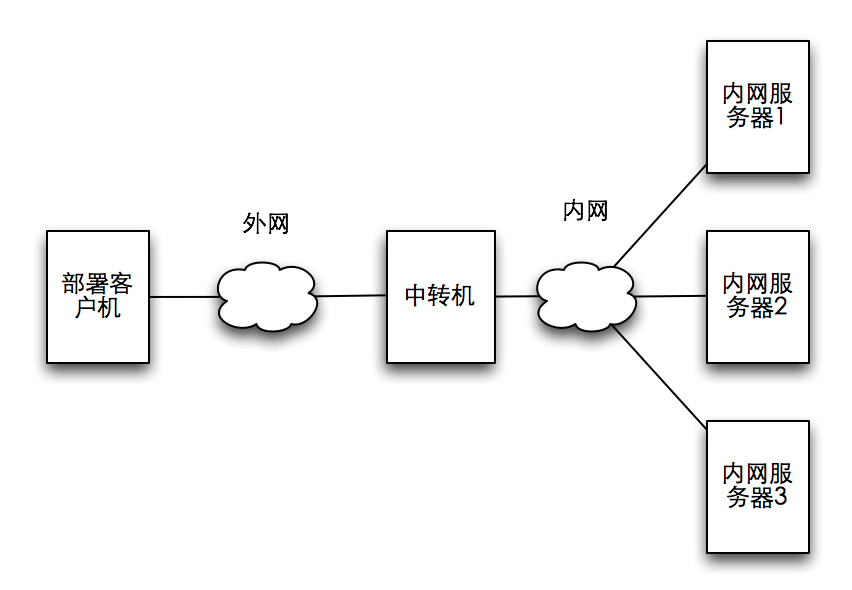
仔细分析后,发现某些活跃的 Group 的 group_requests 增加(当有新申请时)和更改(当通过或拒绝用户申请时)异常频繁,而这些操作经常长时间占用写锁,导致整个数据库阻塞。原因是当有增加 group_request 操作时,Group 预分配的空间不够,需要重新分配空间(内存和硬盘都需要),耗时较长,另外 Group 上建的索引很多,移动 Group 位置导致大量索引更新操作也很耗时,综合起来引起了长时间占用锁问题。
moduleFoodefself.included(base)base.class_evaldodefself.method_injected_by_foo...endendendendmoduleBarincludeFoodefself.included(base)base.method_injected_by_fooendendclassHostincludeFoo# We need to include this dependency for BarincludeBar# Bar is the module that Host really needsend
上面例子中 Host 为了 include Bar,必须得先 include Bar 依赖的 Foo,这是因为 Bar 在 include Foo 时,只是为 Bar extend method_injected_by_foo 方法,所以 Host 必须显式的 include Foo,才能够 extend method_injected_by_foo 方法。
使用 Concern 后,代码可以简写为
12345678910111213141516171819202122232425
require'active_support/concern'moduleFooextendActiveSupport::Concernincludeddoclass_evaldodefself.method_injected_by_foo...endendendendmoduleBarextendActiveSupport::ConcernincludeFooincludeddoself.method_injected_by_fooendendclassHostincludeBar# works, Bar takes care now of its dependenciesend
Bar 和 Foo 都 extend ActiveSupport::Concern 后,Host include Bar 已经不需要事先 mix Foo。
modulemoduleConcerndefself.extended(base)base.instance_variable_set("@_dependencies",[])enddefappend_features(base)ifbase.instance_variable_defined?("@_dependencies")base.instance_variable_get("@_dependencies")<<selfreturnfalseelsereturnfalseifbase<self@_dependencies.each{|dep|base.send(:include,dep)}superbase.extendconst_get("ClassMethods")ifconst_defined?("ClassMethods")ifconst_defined?("InstanceMethods")base.send:include,const_get("InstanceMethods")ActiveSupport::Deprecation.warn"The InstanceMethods module inside ActiveSupport::Concern will be "\"no longer included automatically. Please define instance methods directly in #{self} instead.",callerendbase.class_eval(&@_included_block)ifinstance_variable_defined?("@_included_block")endenddefincluded(base=nil,&block)ifbase.nil?@_included_block=blockelsesuperendendendend
关键部分是 append_features 方法,通过阅读 ruby 的文档和源码得知,ruby 在 include 一个 module 时,实际会触发两个方法,一个是 append_features,进行实际的 mixing 操作,包括增加常量,方法和变量到模块中,另外一个是 included 方法,也就是我们常用来作为 include 钩子的方法,默认的 included 是一个空方法,我们通过重载它使钩子起作用。
重载后行为有了很大变化,它的处理分两种情况:
一种是当它被一个有 @dependencies 实例变量的模块被 include 时,直接把自身加到 @dependencies 中,
比如当 Bar include Foo 时,将触发 Foo 的 append_features(base) 方法,此时 base 是 Bar,self 是 Foo,由于 Bar 已经 extend ActiveSupport::Concern,Bar 的 @dependencies 有定义,所以直接把 Foo 加到 Bar 的 @dependencies 中,然后直接返回,没有立即执行 mixing 操作。
当 Host include Bar 时,将触发 Bar 的 append_features(base) 方法,此时
base 是 Host,self 是 Bar,Host 没有 extend ActiveSupport::Concern,所以 Host 的 @dependencies 无定义,将执行下面的分支,首先 include Foo(通过 Bar 的 @dependencies 获得 ),然后 include Bar (通过 super),然后是后续操作。