在薄荷生产系统性能优化中,我们遇到过好几次类似的问题。例如有一个 api 需要返回多个存放缓存的用户资料,单个用户资料缓存读取时间接近 1 ms,50 个用户资料消耗接近 45 ms 时间,它导致这个 api 响应时间很长,把 50 次用户资料缓存读取放到一次批量读取后,缓存读取时间减少为 3 ms 左右,应用性能立即大幅提升。
defwhat_is(obj)caseobjwhen/abc/puts"include abc"when3..5puts"in 3..5"whenSymbolputs"It is a symbol"elseputs"unkonwn"endendwhat_is("abcde")# => "include abc"what_is(4)# => "in 3..5"what_is(:a)# => "It is a symbol"what_is(100)# => "unknown"
case 背后是拿每一个 when 后面的对象与 obj 进行 === 方法计算比较,比如上面的代码就是
分别求 /abc/.===(obj),(3..5).===(obj),Symbol.===(obj)。
关键得看 === 方法里如何定义,Class 类中,=== 定义为 obj.is_a?(klass),所以 case 可以现实 obj 的类型判断。
从中可以看到,mattr_accessor 分别 call mattr_reader 和 mattr_writer,mattr_writer 的主要逻辑是定义类变量(class variable,命名为 @@#{sym}),然后定义类方法 (见 def self.#{sym}=(obj))和普通实例方法(见 def #{sym}=(obj))。当 Person include HairColors 的时候,普通实例方法是 mix 进 Person 的,但类方法并不会被 mix 进 Person。可以用下面更简明的例子演示 include module 并不能 mix 类方法。
12345678910111213141516171819
moduleFoodefmethod1puts"method1 in Foo"enddefself.method2puts"method2 in Foo as class method"endendclassBarincludeFooendBar.new.method1# => "method1 in Foo"Foo.method2# => "method2 in Foo as class method"Bar.method2# => NoMethodError: undefined method `method2' for #<Bar:0x007fdb0a121488>
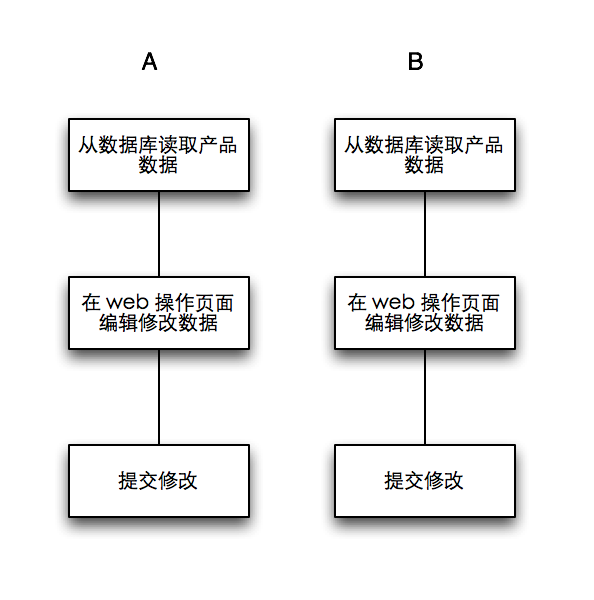
举一个实际的例子:我们的系统里有一个商店模块,商店中重要的一块是对产品信息的管理,比如运营人员常常会编辑产品的信息,包括产品标题,营销口号和价格等等。因为修改十分频繁,碰巧同时编辑提交修改的话,就会偶尔遇到修改丢失的问题,运营人员 A 修改产品标题,运营人员 B 修改价格,A 和 B 提交修改都提示修改成功,但是结果上只是 A 的修改结果生效,B 的修改被 A 的修改冲掉了。
仔细研究原因,发现是因为修改功能缺少操作冲突机制,而修改操作同时发生导致了问题。
如下图所示,A 和 B 同时从数据库中查询数据,在 web 页面中修改同样的数据,提交保存时是以 web 页面中提交的数据为准,从而导致 A 的修改把 B 的修改给覆盖了。